- 移动端


上海吉凯基因医学科技股份有限公司品牌商
15 年
手机商铺
- NaN
- 0
- 0
- 1
- 0




公司新闻/正文
虚拟筛选必看!小分子化合物库评价与选择
839 人阅读发布时间:2025-09-05 10:02

前面的文章我们介绍了虚拟筛选在小分子药物发现中的作用,以及如何提高虚拟筛选命中率和候选化合物类药性能。本文介绍虚拟筛选的小分子化合物库评价和选择方法。
在虚拟筛选中,化合物库本质上是一个由不同分子组成的化学空间,其中每个化合物可视为该空间中的一个点。评价化合物库的质量,可以借鉴评价化学空间的相关指标,主要包括分子多样性、化合物新颖性、化学空间覆盖度、化合物性质分布和数据可靠性等指标,这些指标共同决定了化合物库的适用性,选择指标优化的化合物数据库有助于提高虚拟筛选的成功率,为药物发现提供更优质的候选分子。
另外,虚拟筛选的目标是尽快获得化合物进行生物活性测试,所以化合物库内库存的数量、质量以及供货周期也是化合物库选择要考虑的关键因素。
化合物库分子多样性
分子多样性是指该化合物库的分子结构多样性,评估化合物在骨架结构、官能团、环系统等方面的差异,可以用相似性指数、Murcko骨架分析等方法进行比较。相似性和多样性是两个相互关联的概念,一般用相似性指数来表示,如果两个分子完全相同,则相似性指数为1,完全不同,则为0。相似性分析首先用适当的方法对分子进行扫描,比如使用分子指纹表示分子,常用的分子指纹表示方法如morgan指纹,MACCS指纹等。morgan指纹是基于分子的拓扑结构和半径参数生成的二进制指纹,可以描述分子的结构和相似性,MACCS是基于分子的结构和功能团片段生成的二进制指纹。分子用分子指纹表示之后再用适当的方法计算相似性系数,常用的分子相似性系数如Tanimoto系数(也叫谷本系数),对于两个化合物A和B,Tanimoto系数=∣A∩B∣/∣A∪B∣。化合物库的多样性系数(Diversity Metrics)用于量化库中化合物在化学空间中的分布差异,基于Tanimoto系数的多样性评价方法是计算平均分子间相似度(Mean Pairwise Similarity, MPS),计算库中所有分子对之间的相似性的平均值,MPS越低,化合物库多样性越高,MPS计算方式为:
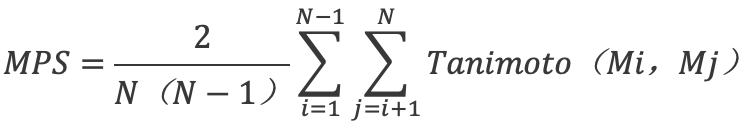
另外,也可以用平均分子间距离(Mean Pairwise Distance, MPD)和分散度来评价化合物库的多样性,MPD越大,分子库多样性越高,MPD计算公式为:
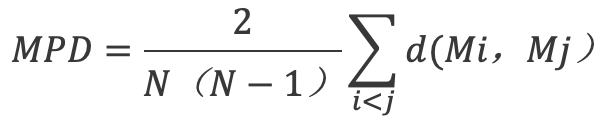
基于分子间距离计算标准差,值越大,离散性越好,标准差的计算公式为:
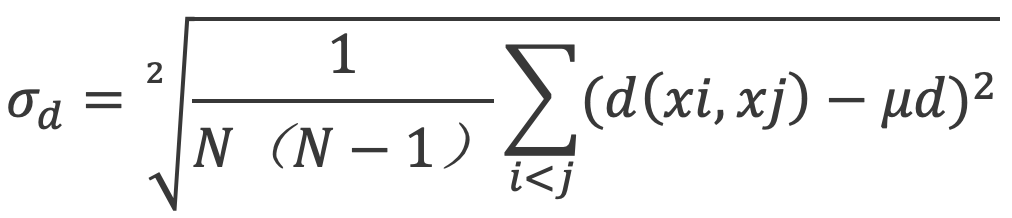
Murcko骨架将将药物分子拆解成四种单元:环结构(ring system)、接头(linker)、骨架(scaffold)和侧链(side chain),其中scaffold由ring system和linker组成。这么分解有多种好处,可以按照骨架结构对化合物库进行聚类分析,化合物库含有的骨架结构越多,分布越广泛,代表该库越优秀,环和侧链代表不同的合成单元,可以据此评价化合物的可合成性,方便化合物从虚拟筛选走入实验室验证阶段,另外,新颖的骨架结构方便药物的整体设计和专利保护,例如专利中的Markush结构通式采用了Murcko骨架类似的表达方式,将分子分为固定结构(骨架)、取代基(支链)和连接片段。
也可以用化合物的物理化学性质分布评价一个化合物库的多样性,通常用类药性质来评价化合物的物理化学性质分布,如分子量、logP、极性表面积、氢键供体、氢键受体、可旋转键数等。下图是chemdiv一个靶向激酶化合物库的多样性评价和物理化学性质分布,可见该化合物库具有很好的多样性和类药性能。
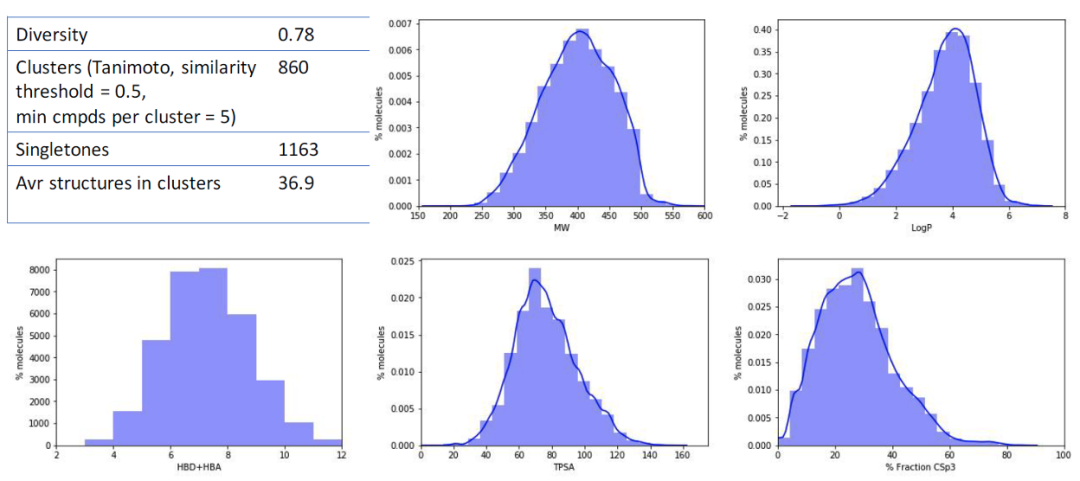
注:图片来源于chemdiv
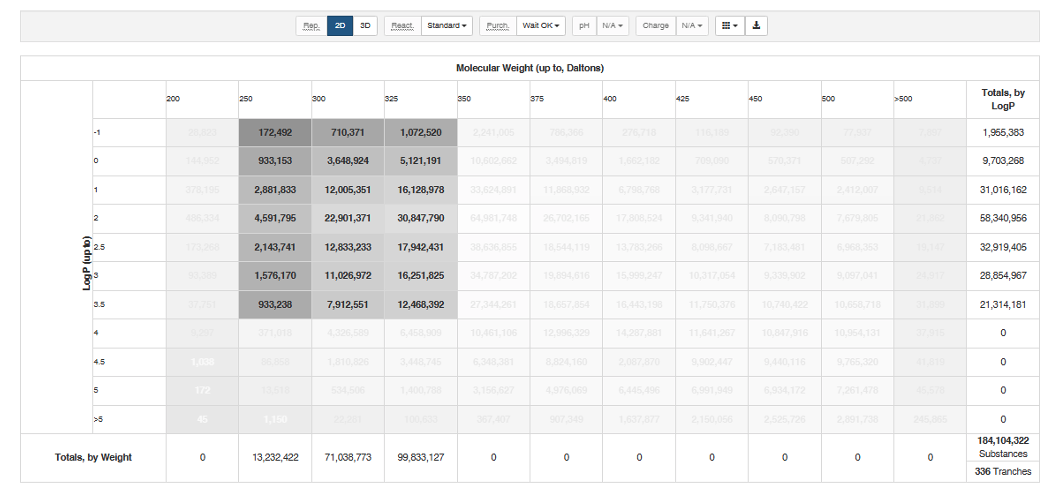
Zinc数据库根据化合物物理化学性质,给出类药性化合物库集合和类先导化合物集合,如下图所示,分子量在250~350之间,logP在-1~3.5之间的类先导分子库有1.84亿个分子。
化合物结构新颖性
化合物库的新颖性是另一个重要的关键指标,是指化合物库中的分子与已知分子的不相似程度,用量化的指标评价该化合物库与已知化学空间的差异程度。既然是评价不相似程度,上文中描述的评价相似度的指标就可以拿来使用,只是使用的方式略有不同。例如可以计算目标化合物与参考化合物库(CHEMBL、PubChem)的最大Tanimoto相似性系数,Tmax小于0.4,代表化合物结构比较新颖,Tmax大于0.8,表示化合物结构不新颖,Tmax的计算公式如下:

前文介绍了分子Murcko骨架,也可以通过比较化合物与参考化合物库的Murcko骨架来判定分子的新颖性,如果Murcko骨架不同,代表化合物新颖。
基于化合物库的空间分布,可以使用最近邻距离(Nearest Neighbor Distance, NND)来评价化合物库的新颖性,NND越大,新颖性越高,NND计算公式为:
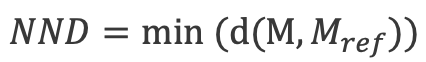
另外,还有其它评价分子新颖性的方法,如基于分子生成模型的评价方法和综合打分评价方法等,感兴趣的读者可以自己阅读相关资料。
在考虑化合物的新颖性的同时,必须考虑化合物库的可及性,快速有效的获得活性化合物,是虚拟筛选的价值所在。通常,如果筛选的实物化合物库,就可以找供应商直接购买,周期最短,如果虚拟筛选的是AI生成库,必须先评价化合物是否能够合成,能够设计合理的合成路线,进行合成。如果筛选最后得到的候选结构式不能合成,那虚拟筛选就失去了意义。一些评价化合物可合成性的方法和公式已经被开发出来,例如RDKit开发了SAscore评分,基于分子碎片、环复杂度和官能团的可及性计算评分,打分值1~10之间,1是易合成,10是难合成。基于逆合成分析的RAsore评分值(0~1),越高表示越易合成。
化学覆盖度(Coverage)
化学空间理论上包含所有可能的有机分子,其数量取决于分子大小和原子组合方式。分子量小于1000的分子是小分子药物研究的范畴,通过枚举算法,估计有1060-10200个分子。目前, 已知的大型化合物库有Zinc数据库,目前有23亿个化合物,其中15亿个可购买,PubChem数据库,有1.22亿个已报道的分子,CHEMBL数据库有249万个生物活性分子,天然产物数据库Coconuts,有69万个天然产物分子。
评价化合物空间覆盖度的方法有很多种,例如,基于物理化学性质的方法,如分子量、logP,PSA的分布,基于分子骨架的骨架类型和数量分布,基于分子相似性分析的平均相似性、最邻近距离NND和分散率分布。基于空间指标的空间覆盖率、空洞分析和密度分析等指标,基于生物活性指标,有类药性分子分布,活性数据覆盖率,化合物库覆盖的靶点类型及数量等指标。
数据质量和数据可靠性
化合物库的数据质量和数据可靠性也是重要的指标,例如,BindingDB主要收集了小分子与蛋白相互作用的数据,数据来源于科学文献和部分制药公司的专利,并通过pubchem和CHEMBL交叉验证,减少错误和重复条目,部分研究者提供的数据由人工校验,确保数据的准确性。商业化的数据库如chemdiv,库存化合物的数量及质量等信息就非常重要,对研究者来说,筛选完成后,可以根据库存数据购买自己需要的化合物,并且可以核对化合物的纯度、质谱和核磁数据,确定库存化合物满足测试要求。
下面给大家简单介绍一些代表性的化合物数据库,这些数据库各有特色,且数据质量可靠,非常具有代表性。
Zinc数据库
ZINC是一个免费开放的化合物数据库,专门为虚拟筛选和药物发现而设计。它由美国加州大学旧金山分校(UCSF)的Shoichet实验室维护,自2005年发布以来,已成为计算化学和药物研发领域的重要资源。
ZINC20(新版本)包含超过23亿个化合物,其中约15亿个可商业购买。此外,还提供数十亿个“按需合成”的虚拟化合物库,供应商可以根据客户要求快速合成。ZINC整合了全球150家化合物供应商的目录,也包含已上市药物、天然产物、片段库等特殊目录。可以根据虚拟筛选需求选择类药库、类先导库、片段库等子集。ZINC特点是包含化合物数量多、可合成,数据库由于数据来源于不同的供应商,数据可能有重复条目。
PubChem数据库
PubChem是由美国国家生物技术信息中心(NCBI)维护的免费开放化学数据库,涵盖小分子、生物活性、药物及相关化学信息。自2004年上线以来,已成为化学、生物学和药学研究的核心资源。Pubchem数据库收录了1.2亿个化合物的结构信息、物理化学性质、专利、科研文献、供应商、高通量筛选结果、活性数据、靶点和实验条件等信息。整合了化学结构、生物活性和文献数据,支持跨领域研究。该数据库数据来源于科研数据、政府机构和供应商,数据可靠性高。
ChEMBL数据库
ChEMBL是由欧洲生物信息研究所(EMBL-EBI)维护的权威药物化学数据库,专注于药物发现相关的生物活性数据。该数据库源于葛兰素史克(GSK)的StARlite项目,2008年由EMBL-EBI接管并发展为开源社区资源。CHEMBL收录了250万化合物,2100万活性数据和16000个靶点,是药物研发导向的数据库,支持按结构、靶点、适应症等多维度进行检索,提供活性、ADME性质和毒性数据,特别关注已上市药物和临床药物。CHEMBL数据来源主要有文献、专利和制药公司的公开数据,并经过严格的人工审核,数据可靠性高。
BindingDB数据库
BindingDB 是由美国国家癌症研究所(NCI)和马里兰大学共同维护的专业数据库,专注于蛋白质-小分子相互作用的定量结合数据。该数据库自2000年建立以来,已成为研究分子识别和药物设计的重要资源。BindingDB收录了130万个小分子和9600个靶点,包含310万条活性数据。BindingDB的蛋白-小分子结合数据包含结合常数(Kd/Ki/IC50)、解离常数(Ka)、热力学参数(ΔG、ΔH、ΔS)和实验条件,这些数据可用于SAR分析和热力学研究。BindingDB数据主要来源于文献和专利,数据可信度高。
COCONUT数据库
COCONUT(Collection of Open Natural products)是当前规模最大的开放天然产物数据库,由欧盟Horizon 2020计划资助开发,专注于收集全球天然来源的小分子化合物信息。COCONUT目前收录了69万个天然产物,来源包括植物、微生物、海洋生物等。COCONUT数据主要来源于已发表的天然产物文献和已有数据库整合,部分数据由实验室直接提交,具有自动去重,标准化处理功能,数据可信度高。
Chemdiv数据库
ChemDiv是全球知名的商业化化合物库供应商,专注于为药物发现和筛选提供高质量的化合物资源。该数据库由美国ChemDiv公司开发维护,包含200多万个结构多样、类药性好的小分子化合物。ChemDiv专门为药物筛选开发了100多个靶向和聚焦化合物库,可以按客户的需求快速交付化合物。ChemDiv还提供多种规格的预配制板多样性化合物子集,可以快速提供给高通量筛选的客户。ChemDiv的化合物质量较高,纯度在90%以上,提供质检谱图,发货快,是虚拟筛选客户的优选供应商之一。
Enamine数据库
Enamine 是全球知名的药物发现化合物供应商,提供超过460万种可供筛选化合物和100亿种可定制合成的化合物空间。其数据库以结构多样性和合成可行性著称,广泛应用于虚拟筛选和药物研发。库存149万种合成砌块分子,可以用于快速合成目标分子,每年新增2万多个新的合成砌块和30万个新分子。根据客户不同需要,可以提供多种靶向化合物库、多样性化合物库、生物活性库、片段库、共价库、基于可靠化学反应的虚拟库等。Enamine数据库是全球最大的可合成化合物库,化合物均通过可合成性验证,支持AI驱动的分子生成,尤其适合需要快速获得化合物的研究。
扫码了解更多

